2013-04-04
从最原始的查询开始,位于后台某个报表,当用户发起一个查询,我们该干啥呢?
抽象一种最简单的形式,查询是对我们的数据做一定的转换而得来的,即
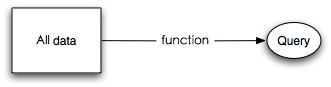
按这样的理解,当用户发起一个查询时,我们可以直接在原始数据集上进行操作, 操作的过程可以在服务端或者客户端。
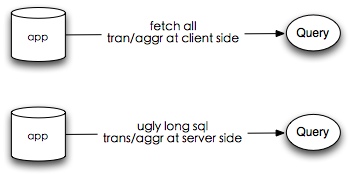
直接在原始数据上操作查询数据是非常艰难的,业务方面的数据并不是那么查询友好,有多个查询需求时得重复很多重复的代码和计算。
于是我们很容易想到上述的模型需要再添加一层预处理层,方便查询。

在实际处理当中,我们本着依靠数据仓库理论武装自己的原则,对原始数据做了系统的预处理后形成了一个数据仓库。
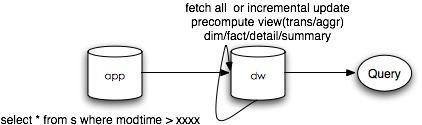
由于引入了预计算,就有了一个数据更新问题。为了抠那一点时间和空间,我们绞尽脑汁想到了一种所谓增量更新( incremental update)的方法,于是数据愉快地更新起来了。
机器或者人工的失误,数据源数据发生了错误或遗失,对于我们的预处理层真是一次灾难啊,没什么好说的,只能重算了。
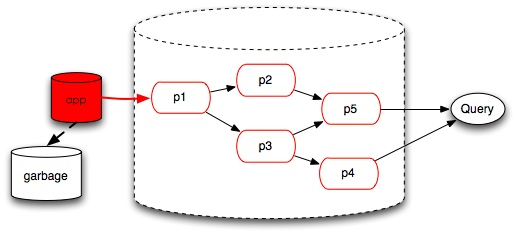
由于数据规模逐渐增加,单机的关系数据库渐渐扛不住了,我们只能引入分布式的处理(mapred)来分担预处理的压力。
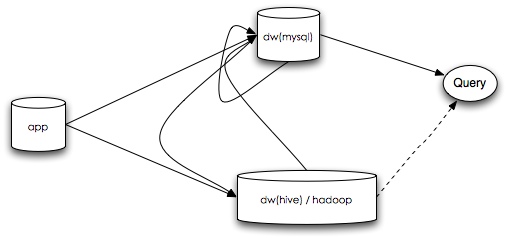
在分布式计算模式下,原有的关系数据库特性已经不在那么好用了。索引剪枝不再好使,增量更新也不易于实现,于是大部分情况下,我们粗暴地全量计算,我们再也不怕历史数据有问题了。
随着预处理数据渐渐地迁移,不可避免地我们需要查询分布式数据库(hive), 这样我们的查询必须支持那种异构的数据源了,我们可以再加上一层,把各类查询都接入。
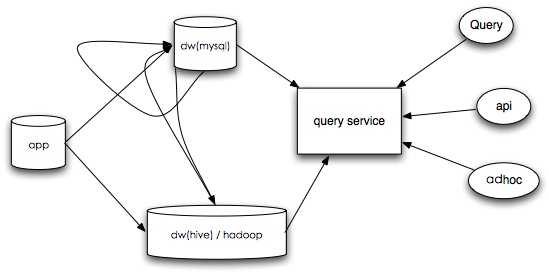
我们称这个新的服务是查询中心,它将作为一切查询的入口,也体现了一种服务化的理念。
当然,各类的查询区别明显,普通报表query 和 api 一般执行快,要求响应也快。对于用户发起adhoc 操作,则可能查询费时也不一定需要及时响应。对于这样一个包容性的服务来说是个考验。
似乎漏了几部分?
- 由于有了预处理,查询数据的实时性不可避免要打折。
- 对于分布式数据库数据访问有点过慢(目前的策略是将聚合结果写回关系型数据库来支持快速查询)。
- 数据应用方面,推荐/搜索相关的线上查询服务设计
- 感觉支持后台数据服务和线上服务还是不能混在一块的
这些都是可改进的点,围绕着查询这个主题。