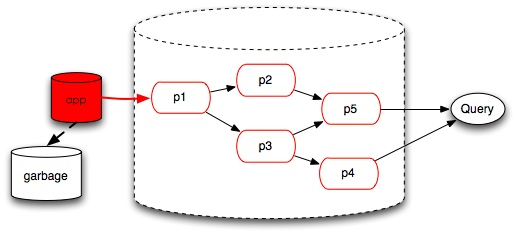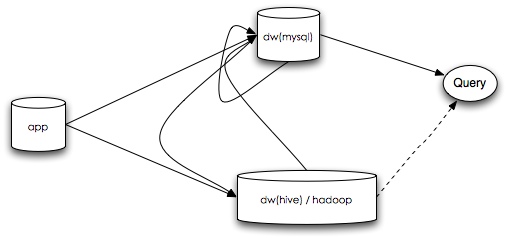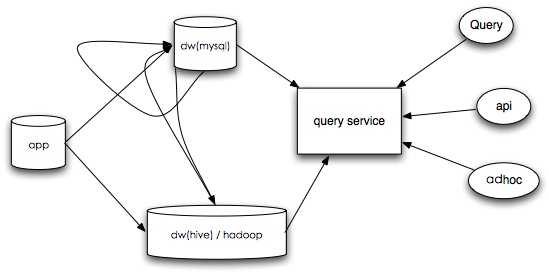
Big Cube 是今天(2014.3.15) 鄙厂第二届黑客马拉松我们队的作品, 我跟 yc 还有 cc 一起搞的。这个名字是我今天随便取的,我们要做的是一个 OLAP 的 demo。
前情提要
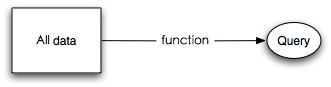
早在12年初我们就在寄希望 OLAP 来帮助数据仓库数据建模,数据解读与分析。当时我们采用的是 mondrian 当时的想法很理想,感觉就是创建几个模型,几个维度,事实,就可以在各种粒度下把各种指标囊括进来,并有统一的地方可以管理指标定义。 后面这个项目失败了,diao总结了一些失败的原因:
开发和使用太复杂, 成本太高
产品成熟度较低, 很多数据需求没法支持
笨重,不太适应互联网公司快速灵活的节奏
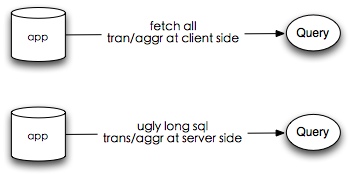
在我看来,当时采用的工具和方案主要还是太慢了,不仅是工具调研与应用,后期的模型开发以及工具使用同样。由于公司发展很迅速,大部分模型都不太稳定,新的事实,维度也经常产生,维度和事实本身也太稳定,部分事实发生之后还会修改。当时的 backend 依赖的是 mysql ,本身也不可扩展。
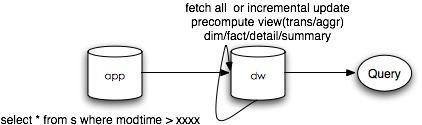
后来 ek 又启动了一个曲线救国的计划,ModelBuilder。这个工具是 ek 独立完成的一个跟 ETL 工具相结合的模型设计工具,通过配置模型可以在hive下生成各种主题各种聚合粒度下的统计指标。在我看来相当于一个自研的 OLAP 服务的核心部分。现在在内部使用也很好,负责的指标和依赖很多。
当然这次 Hackathon 我们使用的是 cubes 这个开源的 OLAP python 包搭建的。早在 12 年我们做 OLAP 的时候,我就发现这个 python OLAP 工具, 不过当时也只是关注,一直都没有尝试使用。这次比赛之前又看了一下,感觉拿来主义十分方便,简单的模型配置还附赠一个前端的模型展示 CubesViewer , 之前提到如果 backend 依赖 mysql 的话,那看起来还是不够完美,所幸 cubes 的 backend 是可以定制化的,其中 sql 类型的 backend 支持所有封装了 sqlalchemy 接口的引擎, 恰巧我们最近上线了 Presto , 看了一下 github,有人已经提供了 Presto 的 sqlalchemy 封装的包 pyHive , 看起来万事俱备了,于是我确定了 Hackathon 就搞这个吧,一个支持海量数据快速响应的 OLAP 服务 demo。
准备工作
在 Hackathon 的前几天我主要是负责前期体验的,这里我想搞清楚的是:
1. 模型表示上是否可以与我们的数据格式对接(或者需要生产新的数据来适应特定格式), 需定一个展示模型,最好有意义
2. presto backend 开发是否有问题(接口是否好用), presto 的SQL语法十分支持cube生成的查询
3. cube server 的性能是否符合预期
4. 前端是否需要再做进一步开发
在13号左右我开始在线下测试第一个 presto backend 的 “hello world” 的case, 发现生成的语句会包含 order by limit offset 的语句,而 presto 不支持 offset 类型的语句, 算是我们后续要解决的一个问题吧。其他问题基本没来得及看。
开幕
15号下午五点如期开场, 兴哥和荣均简单地做了讲话大家便更忙各的了。
14号进展
开始后我们把晚饭定完之后就开始分工着手解决问题, 这里我主要负责模型的选择与数据生成以及配置相关工作, yc 负责 cubeviewer 的适配,cc 负责 presto 相关的查询支持。我们就在自己工位上搞,一起通过 github 共享代码。一开始我打算配置一个较复杂的模型,不过深入去看,感觉还是得一步一步来,先搞定简单的才是, 于是我选择了一个仅有四个维度的已经聚合过的数据作为展示demo。 presto 这边纯爷着手解决 offset 的问题,兴致挺高的,打算在 presto 那边添加这个功能。yc 同学由于要去签租房合同,搞了一会儿就得提前撤了。话说这次我们定的是棒约翰的披萨外卖,挺好吃的,我一下子吃的有点撑。晚上十点我跟cc一起坐班车回家了, 我的进度是配置了一点点模板,cc还在解决 offset 的问题。这里我说的是这次我没有像上一届一样在公司通宵搞这个了,这段时间我一回到家就洗个澡感觉十分舒服,洗完澡之后可以支撑我工作到两点,然后第二天早上七点起来还很有精神。所有我在 Hackathon 也选择回家,洗澡然后第二天再过来。
15号进展
由于 demo 还没有成型,15号早上我六点就醒了开始干活了,感觉 presto 那边做修改可能比较困难,我就在 cubes 这边生成查询时将 order 和 limit 相关子句给去掉了, 算是做了二手准备吧,这样我们的一个简单 demo 才跑了起来。早上七点半我就出发去公司了, 十分兴奋。后面十点多的时候我们三个都到了,大家继续战斗,我让 cc 来一起配合模型编写以及一些前端展示的润色工作,yc 同学还在搞 cubeviewer, 后面他发现一个大bug : cubeviewer 使用的 cubes api 跟最新的 cubes 不兼容 ,当时差点崩溃了。 yc 同学说,"给我两个小时,我把这个bug fix 一下" 。后面 yc 还真的在约定时间内搞出了 api 把 cubeviewer 跑起来了。我们在一旁帮忙测试,发现还是有几个问题:
1. 维度数据没有正确展示
这部分初步猜测是由于 cubeviewer 使用的数据格式同样是老的,导致部分假设面对新的数据格式失效了,导致维度相关数据没有正确展示。
2. 做 filter 的模块没能正确执行
这里我们后面发现是由于 filter 模块的 SQL 模板产生的 SQL 不符合 presto 的语法规范,导致发起的执行失败。
或许还有更多的问题,不过以上两个问题的解决就很花我们的时间了,最终在下午两点半之前也没能很好解决,时间到了,只能硬着头皮上台演示了。
我们抽到了第四个演示,我简单做了四页 ppt,又开了两个查询页面展示我们的 demo,不过可能是演讲技巧的问题,异或展示demo不够清楚,感觉整体展示效果不好。后续我在台下听了后面二十来组的作品,大家的想法都挺出彩的,完成度也很好, 比上一届来说进步了很多。最终我们毫无悬念地没有拿到奖项,anyway,我觉得能在短短的比赛时间内让最初的想法 work 我已经很满意了,后续还可以在这个点上继续开发,可以期待后续给用户提供这样遍历的分析引擎是非常牛逼的。
后续改进
- 将 cubeviewer 调通, 调整 sql backend 查询语句生成让 presto 支持相关查询
- 测试 model viewer & model builder 组件, 方便观察和编辑model,可以做到自动 reload model 文件那就再好不过了。
- 添加 label, 多语言支持(主要是中文)
- 在适当的地方添加 cache
总结
本次 Hackathon 由于有强大的队友的加入,再加上确定的计划与目标,故一切尽在掌握当中。当然时间还是没能有剩余,没能达到最佳状态。我看有些组的作品其实也不全是这两天的工作,不过感觉也无可厚非,毕竟牛逼的想法本来也不是一天之内就可以很好的 prototype 出来的。下次也许我们也可以这样来,多做一些准备工作,尽量想清楚所有可能出问题的地方以及相应的解决方案,这样在实际动手时才不会慌张。
后记
又看了多年之前的 mondrian, 发现现在它貌似也很牛逼了,后端也支持很多 SQL backend: 支持 impala , presto , red-shift 。部分还属于初步阶段,不过应该也是激动人心的提高,比12年好多了。